Writing A Data Connector
This data connector is based on AssemblyScript.
Writing a Data connector
If you wish to use any sort of external data in a job or app, you will need a data connector.
The Goal
In this example, we will set up a data connector that returns the average interest rate on the US Treasury Securities for the past 'n' number of months. See the US Treasury's Fiscal Data site for more information.

Data Connectors need to be deterministic for proper consensus to occur. There is no specified date on this API call, but the data is updated with each meeting of the FOMC which is infrequent (over a month). Updates in close proximity to execution could cause problems.
Getting Started
To get started we will use the AssemblyScript template repository which is available on Github. This repository contains a template for the data connector which can be used to fetch swaps from the Uniswapv3 subgraph, and convert the swaps into candle data. This connector could be edited for most types of GraphQL calls or used for making candles from another dataset.
Project Structure
Data Connectors have 3 functions that will be directly called by the Keeper nodes during runtime. These functions are necessary along with configuration form function, other helper functions and classes will likely be helpful. For more information please see the V1 Data Connector Interface. However, this design means that developers only need to implement the methods that are required for the data connector to work.
Below are the significant files and folders which you will want to get familiar with:
├── assembly // Source code for the data connector
├── build // Output of the build process aka `yarn asbuild`
├── coverage // Coverage report for testing
├── tests // Test files with a built in test runner
├── asconfig.json // Assemblyscript config
├── package.json // Dependencies for the data connector
The template comes with as-json which is a JSON serializer and deserializer.
Project Setup
First, clone the Data Connector Template
git clone https://github.com/SteerProtocol/data-connector-template-assemblyscript
Then, switch to the v1-example branch
git checkout v1-example
Lastly, install the dependencies with Yarn
yarn install
Once you have set up your project, you can begin defining your data connector.
Setup Data Connector Params
If you are not familiar with JSON Schema the following guide is very helpful: JSON Schema Guide
For our goals, we will only require the number of months in the past to pull data for. The object limit for a single page of data is 100, and since we are targeting treasury bills, notes, and bonds, we will impose a max of 33 months. We could paginate to get even more data, but this should suffice for our goal. We add a numMonths parameter to our input config.
You can find an online JSON Schema builder with examples here: Online JSON Schema Builder
At the bottom of the template, you will find the config which we will update with our own configuration form.
export function config(): string {
return `{
"title": "Average Interest Rates on US Treasury Securities",
"description": "Returns arrays of interest rates for treasury bills, notes, and bonds",
"type": "object",
"required": [
"lookback"
],
"properties": {
"numMonths": {
"type": "integer",
"title": "Number of months",
"description": "Number of months back from the present to pull data from"
}
}
}`;
}
Once you have defined your config, any parameters must be initialized with the initialize function. The predetermined timestamp will also be passed to be used in any calls requiring time-specific information.
@serializable
class Config {
lookback: i32 = 0;
isValid(): boolean {
if (!this.lookback) return false;
return true;
}
}
export function initialize(config: string): void {
configObj = JSON.parse<Config>(config);
if (!configObj.isValid()) throw new Error("Config not properly formatted");
if (configObj.lookback > 100) throw new Error("Config lookback cannot exceed 100!");
}
Request & Response Logic Implementation
Now that we have all instance specific parameters we need, the node will call our execute function. The execute function takes in a string as input, which on the first call will always be an empty string: "". This signals the bundle that the first request payload should be returned. The Keeper Node runs off of Axios' request framework. The bundle should return request config objects as strings to the node. The Keeper node makes an Axios request with said config, and will return the response data back the the bundle by calling the execute function and passing the data as a parameter. To signal to the Keeper node that the callback loop should terminate, the execute function should return the string: "true". In this example we will only require one call to fetch all the data needed, but more complex logic can be written to parse through the data returned to see if conditions are met.
V2 Data Connectors not only provides the fetch() api, but offers CCXT and an improved developer experience
export function execute(res: string | null): string {
if (!configObj) throw new Error("Missing config: Must call config() first!");
if (!res) {
return `{
"method": "get",
"url": "https://api.fiscaldata.treasury.gov/services/api/fiscal_service/v2/accounting/od/avg_interest_rates?sort=-record_date&filter=security_desc:in:(Treasury Bills,Treasury Notes,Treasury Bonds)",
"headers": {}
}`
}
data = JSON.parse<ResponseObj>(res).data;
return "true";
}
There are dozens of ways to implement the callback logic. The exact design will depend on the data you are fetching, make sure to test your bundle.
To walk through the process again, the node will call execute where the response parameter will initially be null. We catch this in our 'if statement,' and return the Axios request config object for the node to call. Execute is called again, this time with the response parameter set to the response from our Axios call. We then parse the response and set our array.
Transform
With the conclusion of the execute callback loop, the Keeper node will call transform which returns the data in its final shape for the execution bundle. In our case, all calls will return 100 objects of our selected securities. Since we have a desired number of months, we simply splice our ordered data (already sorted by date from the api) and make our final payload.
We also make a helper function to extract the interest rate from the object.
export function transform(): string {
const bills: Array<f64> = [];
const notes: Array<f64> = [];
const bonds: Array<f64> = [];
for (let i = 0; i < data.length - 1; i += 3) {
bonds.push(f64.parse(data.at(i).avg_interest_rate_amt));
notes.push(f64.parse(data.at(i + 1).avg_interest_rate_amt));
bills.push(f64.parse(data.at(i + 2).avg_interest_rate_amt));
}
return `{
"bills": [`+ bills.toString() + `],
"notes": [`+ notes.toString() + `],
"bonds": [`+ bonds.toString() + `]
}`;
}
Running
To run the Data Connector, first build the .wasm files and then execute index.js or index.ts in the base directory
yarn build:debug
node index.js
You should see the following output:
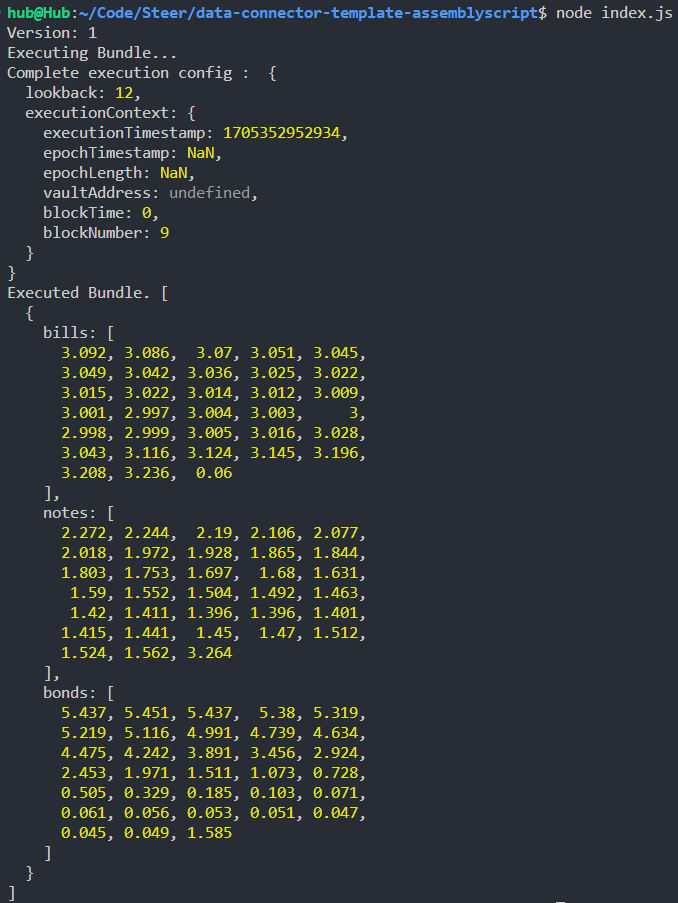
Testing
The template comes with a number of tests simulating the various calls from the node and the front end fetching the config form. There are tests for validating the config, the first call of execute, the nth call of execute, the last call of execute, and finally the transformation. You may need less or more tests depending on your data connector.
Let's make sure the test can run by using the following command:
yarn test
You should see the following output:
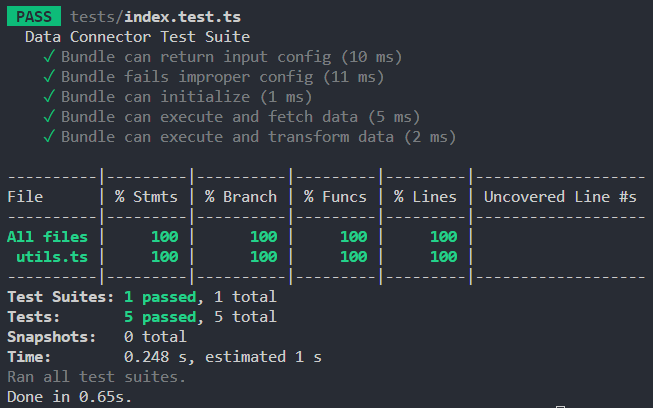
Final Result
As you can see, it is very quick to create a simple data connector for the Steer Protocol! By having custom parameters and calling through axios, we are able to have a flexible platform for fetching data. Transforming the data can shape things as needed to be consumed by an app or execution bundle. In the end, the decentralized and deterministic fetching of data provides a fast and secure way of bringing information on-chain.
Next Steps
Use the Steer Protocol Backtesting Platform to test your app!
Steer provides a state-of-the-art backtesting platform for all concentrated liquidity apps! Run your execution bundle on historical data and see how it would have performed! Examine risks and debug your app to improve its performance. You can find more information about this tool in the Steer Backtesting Documentation.